The first iteration: Make It Work
At the heart of the text compression is the algorithm that builds the dictionary of most frequent substrings. The original algorithm focuses a lot on keeping the dictionary size limited. It does so by applying strategies for adding new substrings, and removing the least frequent ones when the size limit is reached. There’s a lot of room for experimentation here.
For the first iteration, I’ve decided to build a simpler version of the dictionary construction algorithm. My goal is to focus more on the end-to-end solution, which includes the following steps:
- Build the dictionary of most frequent substrings.
- Encode the text using the dictionary.
- Decode the text back to the original form.
In particular, I assume that the dictionary is not limited in size during the construction. I’m going add as many substrings as I want, and not care about pruning. Once the dictionary is built, I select the first N substrings that give the best compression gain. Also, I’m going to build the encoder that would compress UTF-8 encoded strings, and the decoder to do the reverse.
At this stage, I’m also not concerned about the performance. I’m just going to build the simplest possible solution that would work, and then I’ll start optimizing.
Finally, I’m not bothered about a proper error handling. Rust has a special way of handling errors using the Result type, but for the time being I’m ok with just panicking at runtime if anything goes wrong. I make a note of the places where proper error handling should be implemented, and will come back to it later.
Building the dictionary
Once we have all simplifications to the algorithm, the flowchart looks like this:
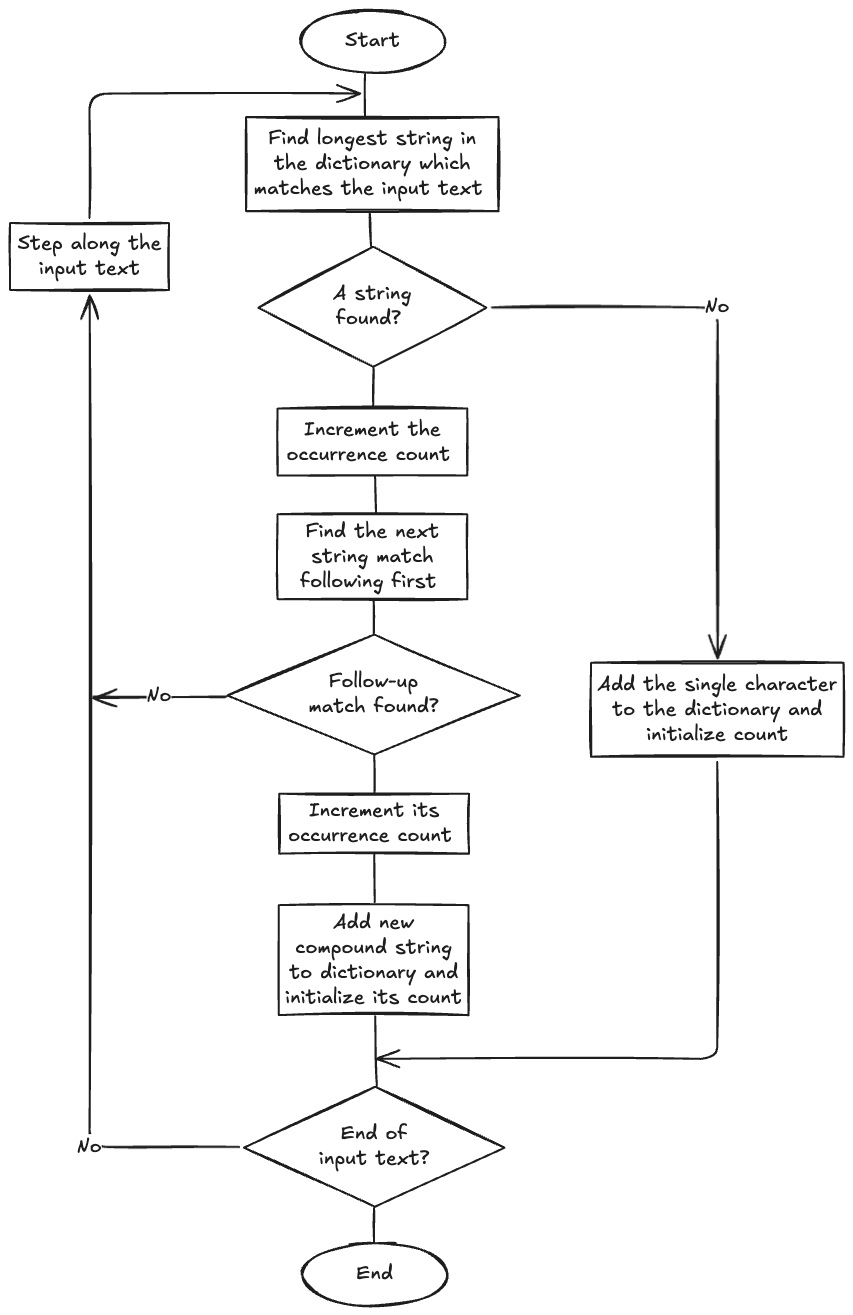
To manage the dictionary of substrings while it’s being built, I’ve introduced a data type called SubstringLedger. Based on a hash map of substrings and their counts, it provides methods to find matching substrings, add new substrings, and increment the counts of existing ones. With the help of this type, the whole algorithm is implemented in a single function called build_ledger:
pub fn build_ledger(source: &str) -> SubstringLedger {
let mut ledger = SubstringLedger::new();
let mut head: &str = source;
while let Some(next_char) = head.chars().next() {
if let Some(substr_match) = ledger.find_longest_match(head) {
let rest = &head[substr_match.len()..];
if let Some(follow_up_match) = ledger.find_longest_match(rest) {
ledger.increment_count(&follow_up_match);
let new_substring = substr_match.clone() + &follow_up_match;
ledger.insert_new(&new_substring);
head = &head[new_substring.len()..];
} else {
head = rest;
}
ledger.increment_count(&substr_match);
} else {
let new_substring = next_char.to_string();
ledger.insert_new(&new_substring);
head = &head[new_substring.len()..];
}
}
ledger
}
Encoding scheme
My program works with UTF-8 encoded strings, which are natural in Rust. The question is how to embed the substring replacements into the encoded text, so that we don’t confuse them with uncompressed portions. The answer here is to use a special marker byte to indicate the replacement. The marker byte should be a value that would never occur in the original text, so that we don’t mistake it for an uncompressed portion at the decoding stage.
As per the UTF-8 specification, there are bytes that could never appear in a valid UTF-8 string. In particular, bytes 0xF5-0xFF are invalid. I chose to use 0xF5 as a marker, and the substring replacement will be a 2-byte sequence of a form 0xF5 0xNN, where NN is the index of the substring in the dictionary. That would limit the total number of representable substrings to 256, but that should be enough for starters.
As a slight future improvement, I could expand the size of the dictionary beyond 256, still using 2 bytes for the representation. Since the entire range 0xF5-0xFF is not represented in the UTF-8, I can use the portion of the marker byte as a part of the index. That would allow me to increase the dictionary size to 11 * 256 = 2816 substrings. I might consider it later, when I start playing with optimizations.
Selecting the most impactful substrings
Once all substrings are discovered in the source text, we need to select the top 256 that give the most impact on compression. One approach is to select the longest ones, but that might not be the best.
Let’s consider the following example. Suppose I have a substring ‘CAMELOT’ that appears in the text 2 times, and the substring ‘CAME’ with 10 occurrences. If I pick ‘CAMELOT’, I would save (len('CAMELOT') - encoded_size) * count('CAMELOT') = (7 - 2) * 2 = 10 bytes. On the other hand, if I pick ‘CAME’, I would save (len('CAME') - encoded_size) * count('CAME') = (4 - 2) * 10 = 20 bytes. Obviously, the second option is better for compression.
So when I build the result dictionary, I calculate the compression gain for each substring, order them by the gain in descending order, and pick the top 256 from the list. It’s implemented in the SubstringLedger::get_most_impactful_strings method:
pub fn get_most_impactful_strings(&self, encoder_spec: &EncoderSpec) -> SubstringDictionary {
let impacts = self.calculate_impacts(encoder_spec);
let mut most_impactful: Vec<String> = impacts
.into_iter()
.map(|impact| impact.substring.clone())
.take(encoder_spec.num_strings)
.collect();
most_impactful.sort_by(|a, b| compare_substrings(a, b));
SubstringDictionary::new(most_impactful)
}
fn calculate_impacts(&self, encoder_spec: &EncoderSpec) -> Vec<EncodingImpact<'_>> {
let mut impacts: Vec<EncodingImpact> = self
.substrings
.iter()
.map(|(string, &count)| EncodingImpact {
substring: string,
compression_gain: encoder_spec.compression_gain(string, count as usize),
})
.filter(|impact| impact.compression_gain > 0)
.collect();
impacts.sort_by(|a, b| b.compression_gain.cmp(&a.compression_gain));
impacts
}
Trying out the first version
Once I have the the first version end-to-end working, let’s go on an try it out on a few samples.
What I’m interested in is:
- Does it do encoding and decoding correctly (obviously);
- The compression ratio;
- Most common substrings found in the text;
- Time performance compressing texts of different lengths.
To keep things simple, I just grabbed Shakespeare’s Hamlet from the Web, and created a few samples from it, taking first 100, 200, 400, 800 and 1600 lines from the text. I wrote a simple main program to perform the encoding / decoding round on each, and record the data that interests me.
Here are the results we get after running this program:
| File Name | Source Length (chars) | Compression Ratio | Time (seconds) |
|---|---|---|---|
| hamlet-100.txt | 2,763 | 41.40% | 0.25 |
| hamlet-200.txt | 7,103 | 33.99% | 1.09 |
| hamlet-400.txt | 16,122 | 32.22% | 4.42 |
| hamlet-800.txt | 32,894 | 30.43% | 15.50 |
| hamlet-1600.txt | 67,730 | 28.67% | 54.51 |
And the top 5 substrings the algorithm found in the hamlet-1600.txt file are as follows:
1: ".\n "
2: " Exe"
3: " "
4: " him.\n "
5: ".\n "
It’s good to see the program working, and even giving some sensible results! I’m curious about the compression ratio, it’s clear that it goes down as the text length increases. I wonder how much it would go down when the text length is increased further. But another, more worrying thing, is the time performance. It’s clear that the running times grows rapidly as the text length increases. Let’s put that data into a graph.
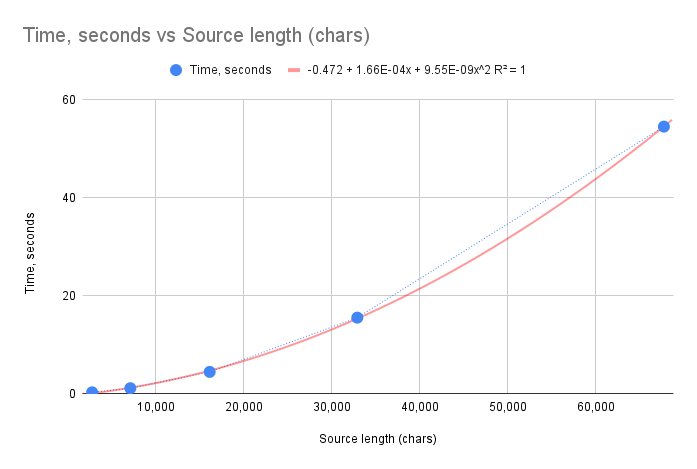
That absolutely looks like a quadratic curve, and the running time for 1600 lines of 54 seconds (sic.: for the debug build, which is not optimized) is preventing me from doing any experiments with larger texts. It’s quite obvious that I need to optimize the algorithm before I can move forward.
Next steps
The implementation of the first iteration is available in the 0.0.1 release. It’s reassuring to see the the program working, but the performance is absolutely abysmal. As the next step, I’m going to tackle the performance issues before I move forward with the algorithm.