Tackling the performance bottleneck
So far, I’ve done the round of performance profiling, and identified the bottleneck. In this post, I’m going to describe how I tackled the problem. Spoiler alert: I only alleviate the performance issue, but not solve it completely for now.
HashMap and BTreeMap
Rust’s standard library provides two different data structures to work with key-value pairs: HashMap and BTreeMap.
HashMap is probably the default choice for most use cases. This data structure is optimized for fast lookups, effectively ensuring constant time performance for inserting, deleting, and accessing elements by key. The data type of the key is required to implement the Hash and Eq traits. Implementing the efficient hash function is a non-trivial task, but luckily, in most cases we can rely on the default implementations for the standard data types. For custom types, the magic #derive macro1 can be used to automatically generate the required implementations. It’s quite common to see #[derive(Hash, PartialEq, Eq)] in the declarations for the types that are used as keys.
But HashMap has a significant drawback for my current use case: it doesn’t preserve the order of the keys. When I iterate over the substrings with HashMap::keys() method, they will be returned to me in a somewhat random order, and so I always have to sort them by the substring length to find the longest match. It’s clear that at the moment my program is spending most of the time doing exactly that. So I need a different data structure, the one that keeps the map’s keys ordered at all times. Enter BTreeMap.
In contrast, BTreeMap keeps the keys ordanized in a tree structure, called B-tree. Essentially, B-tree is a balanced tree that taks advantage of the CPU memory cache, so it works better than a regular binary tree on modern CPU architectures. BTreeMap provides logarithmic time complexity for accessing the elements by key, but more importantly for us, BTreeMap::keys() always keeps the keys in a sorted order, hence eliminating the need for sorting them each time. BTreeMap requires the key type to be sortable, meaning that it must implement the Ord trait. Sometimes we can get away with default implementations, provided by the #[derive] macro, but in my case I have a custom sorting order, so I need to implement the Ord trait manually.
Comparison traits in Rust
There is a family of traits in Rust that are used to compare values, namely PartialEq, Eq, PartialOrd, and Ord. These traits have special significance, because if they are present, the compiler will automatically use them for comparison operators, such as ==, != (for PartialEq), and <, <=, >, >= (for PartialOrd). There also needs to be consitence in the implementation of these traits, e.g. x == y and x <= y must not contradict each other. This is especially important in case you use #[derive] some of these traits, and manually implement others.
The Ord trait is the most important one for my use case, because it’s required for the BTreeMap data structure. It is also the strongest one, meaning that the type also needs to implements PartialOrd, PartialEq, and Eq, in a consistent way. The recommendation here is:
if you derive the implementation for
Ord, you should also derive all four traits. If you implement it manually, you should also implement all four traits, based on the implementation ofOrd.
Why separating comparison into multiple traits?
Briefly speaking, the separation of different comparison operations into multiple traits adds granularity to what operations are available for the particular data type. For example, some types may support only equality, but not ordering (e.g. vectors of values). Similarly, some algorithms may only need partial order to work. All in all, that separation allows for more flexibility when writing generic algorithms.
The newtype design pattern and the Substring type
Rust gives you some flexibility on how you can implement traits on data types. In particular, what you can do is:
- Implement an external trait for your custom data type. That’s similar to, for example, Java’s interfaces, where you can implement an external interface for your class.
- But in addition to that, you can also implement your own trait on an external type.
However, you can’t implement an external trait on an external type: at least one of them has to be local to your crate. This is called the orphan rule. To work around this restriction, the common way is to use a newtype pattern. The idea is that you define a wrapper type around the external one, usually using a tuple struct, and then implement the necessary traits on the wrapper type.
So I introduced a new type Substring to wrap the String type, and then I was able to implement the Ord trait on it:
#[derive(PartialEq, Eq, Clone, Debug)]
pub struct Substring(pub(crate) String);
impl Ord for Substring {
fn cmp(&self, other: &Self) -> Ordering {
let by_length = (other.0.len()).cmp(&self.0.len());
if by_length.is_eq() {
self.0.cmp(&other.0)
} else {
by_length
}
}
}
impl PartialOrd for Substring {
fn partial_cmp(&self, other: &Self) -> Option<Ordering> {
Some(self.cmp(other))
}
}
For my purposes, I implemented the Ord trait such that the strings are compared by length first (in descending order), and only if their lengths are equal, the strings are compared lexicographically. I also provided the implementation of the PartialOrd trait. PartialEq and Eq are derived, which somewhat contradicts the previous recommendation. But in this case, it seems that the default implementation is exactly what I need.
Obviously, after that I had to change the SubstringLedger to use the BTreeMap with the Substring type as the key.
The benefits of the newtype pattern
In addition to that use case when we need to bypass the orphan rule, the newtype pattern is very useful for the following reasons:
- It gives you a natural place to put additional methods that are specific to your data type.
- It allows you to use the specific data type elsewhere in the code, eliminating the ambiguities. Consider, for example, a function
set_password(username: &str, password: &str). It’s very easy to accidentally mix up the arguments of this function, and pass them in the wrong order: the password instead of the username and vice versa. If instead your signature looked likeset_password(username: &Username, password: &Password), the compiler would catch this mistake. - It allows you to add special constraints on the wrapped values. In the previous example, we could restrict
Passwordto be at least 8 characters long. That validation can be done when constructing the instance ofPassword, and then the rest of the code can assume that the password is valid without having to repeat the validation logic.
All in all, I like to use this pattern to improve the readability of my code. It’s worth mentioning that in Rust newtypes are zero-cost abstractions: there’s no overhead in using them, and the compiler will optimize them away.
The results after the change
Having done all the changes, I can now run the new version of the program. Here are the results of running the main program after the change:
| File Name | Source Length (chars) | Compression Ratio | Time (s) |
|---|---|---|---|
| hamlet-100.txt | 2,763 | 41.40% | 0.05 |
| hamlet-200.txt | 7,103 | 33.31% | 0.16 |
| hamlet-400.txt | 16,122 | 32.17% | 0.55 |
| hamlet-800.txt | 32,894 | 30.04% | 1.77 |
| hamlet-1600.txt | 67,730 | 28.67% | 5.75 |
| hamlet-3200.txt | 136,410 | 28.79% | 18.73 |
| hamlet.txt | 191,725 | 28.97% | 32.88 |
And the top 5 common substrings extracted from the entire text of “Hamlet” go as follows:
1: ".\n Exeunt.\n\n\n\n\nScene II.\nElsinore. A"
2: "follow.\n Exeunt.\n\n\n\n\n"
3: ".\n Exeunt.\n\n\n\n\n"
4: ".\n Exeunt.\n\n"
5: ".\n "
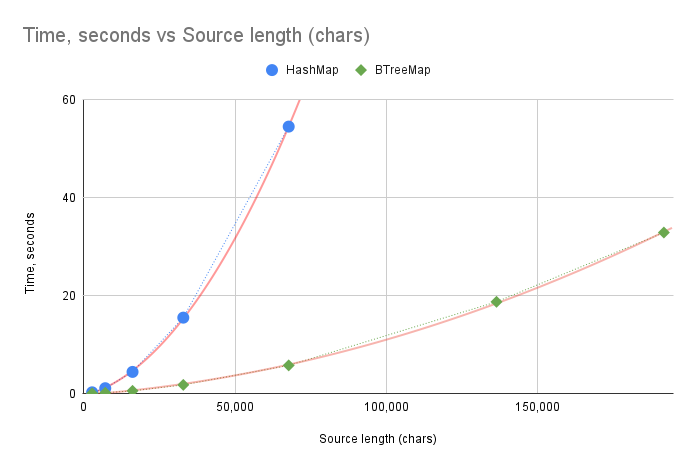
Clearly, the performance has become much better: encoding 1600 lines of “Hamlet” takes 5.75 seconds, versus 54.51 seconds from the previous results. However, the increase in execution time with the text length is still not ideal. Despite the obvious improvement in absolute numbers, the execution time growth curve still looks polynomial to me.
Since the execution time has fallen dramatically, I can now run the performance test on the entire text of “Hamlet”. Here’s how the flamegraph looks (click to enlarge):

SubstringLedger::find_longest_match() is still the bottleneck, but the situation has changed. I got rid of the excessive sorting, and now most of the time is spent in trying to find the matching substring in the dictionary.
When trying to find the match, we iterate over all keys in the map. It’s clear that, since currently the size of the substring dictionary is not limited, the time to go through all keys is going to grow linearly with the dictionary size. On top of that, at each step we check if the current substring matches the start of the text. That in itself is a linear operation, and it will take more and more time, as we accumulate progressively longer substrings as keys. I think that explains the polynomial growth of the execution time.
The verdict
So, the switch to BTreeMap was a clear benefit in terms of performance, but the polynomial growth of the execution time is still an issue. For now I can see two ways to further improve the performance:
- Find a better data structure to store the substring ledger that won’t involve the scan of the entire list of substrings to find the match, or:
- Move to the next stage of the project, in which the size of the dictionary will be limited during construction, which by extension should reduce the time spent in
SubstringLedger::find_longest_match().
Option 1 is a very interesting problem to tackle, but I feel that I may be falling a victim to the premature optimization here. Since I haven’t yet implemented the entire algorithm, I might be spending too much time optimizing the wrong thing. So for now, I’m more tempted to move forward with option 2. Once I have at least a simple way to limit the size of the dictionary, I can come back to tackling the performance issues again, but this time with all pieces of the implementation in place.
Next steps
So I’m now ready to move forward and implement the next stage of the project: the strategy for adding new substrings and pruning the old ones. But before I go on with that, I’d like to tackle a few bugs that I’ve found so far :-).
-
#derivemacro is widely used in Rust programs, but it looks like magic to me. That deserves a separate exploration, so for the time being I assume that it “just works”. ↩